
Blogs, Technology & Trends
What is Processor ? पूरी जानकारी हिंदी मे।

Jul
Leave a Comment/Site Review/By Ankit Kushwaha
हेलो दोस्तों मैं अंकित कुशवाहा आज के अपने इस आर्टिकल में आप सभी का हार्दिक स्वागत करता हूँ। दोस्तों आज मैं अपने इस आर्टिकल के जरिए What is Processor ? पूरी जानकारी हिंदी मे, के प्रकार के बारे में बताने वाला हूँ। तो चलिए शुरुआत करते हैं…
what is processor – कंप्यूटिंग और कंप्यूटर विज्ञान में, एक प्रोसेसर या प्रसंस्करण इकाई {एक विद्युत} तत्व (डिजिटल सर्किट) है जो बाहरी ज्ञान आपूर्ति, अक्सर स्मृति या अन्य ज्ञान धारा पर संचालन करता हैं । यह आमतौर पर एक माइक्रोप्रोसेसर का प्रकार लेता है, जिसे एकल धातु-ऑक्साइड-अर्धचालक एकीकृत सर्किट चिप पर लागू किया जा सकता है। पूर्व में, कई विशिष्ट व्यक्ति वैक्यूम ट्यूबो का उपयोग करके प्रोसेसर का निर्माण किया गया है, कई विशेष व्यक्ति ट्रांजिस्टर,या कई अंतर्निर्मित सर्किट। आज, प्रोसेसर अंतर्निर्मित ट्रांजिस्टर का उपयोग करते हैं।

एक सिस्टम में सेंट्रल प्रोसेसिंग यूनिट (CPU) के साथ चर्चा करने के लिए समयावधि का लगातार उपयोग किया जाता है। हालांकि, यह संभवतः ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) के समान विभिन्न कोप्रोसेसरों के साथ भी चर्चा कर सकता है।
पारंपरिक प्रोसेसर आमतौर पर ज्यादातर सिलिकॉन पर आधारित होते है; फिर भी, शोधकर्ताओ ने प्रायोगिक प्रोसेसर विकसित किए है जो ज्यादातर कार्बन नैनोट्यूब, ग्रैफेन, और आवर्त सारणी के तीन और पांच टीमों के भागों से बने मिश्र धातुओ की तरह विभिन्न आपूर्तियो पर आधारित हैं।सिलिकॉन परमाणुओं की एक शीट से एक परमाणु लंबा और अलग-अलग 2D आपूर्ति से बने ट्रांजिस्टर को प्रोसेसर मे इस्तेमाल करने के लिए शोध किया गया है। क्वांटम प्रोसेसर बनाए गए हैं; वे क्वांटम सुपरपोज़िशन का उपयोग बिट्स (क्विबिट्स के रूप मे जाना जाता है) को केवल एक चालू या बंद अवस्था के विकल्प के रूप में करने के लिए करते है।
Moore’s law
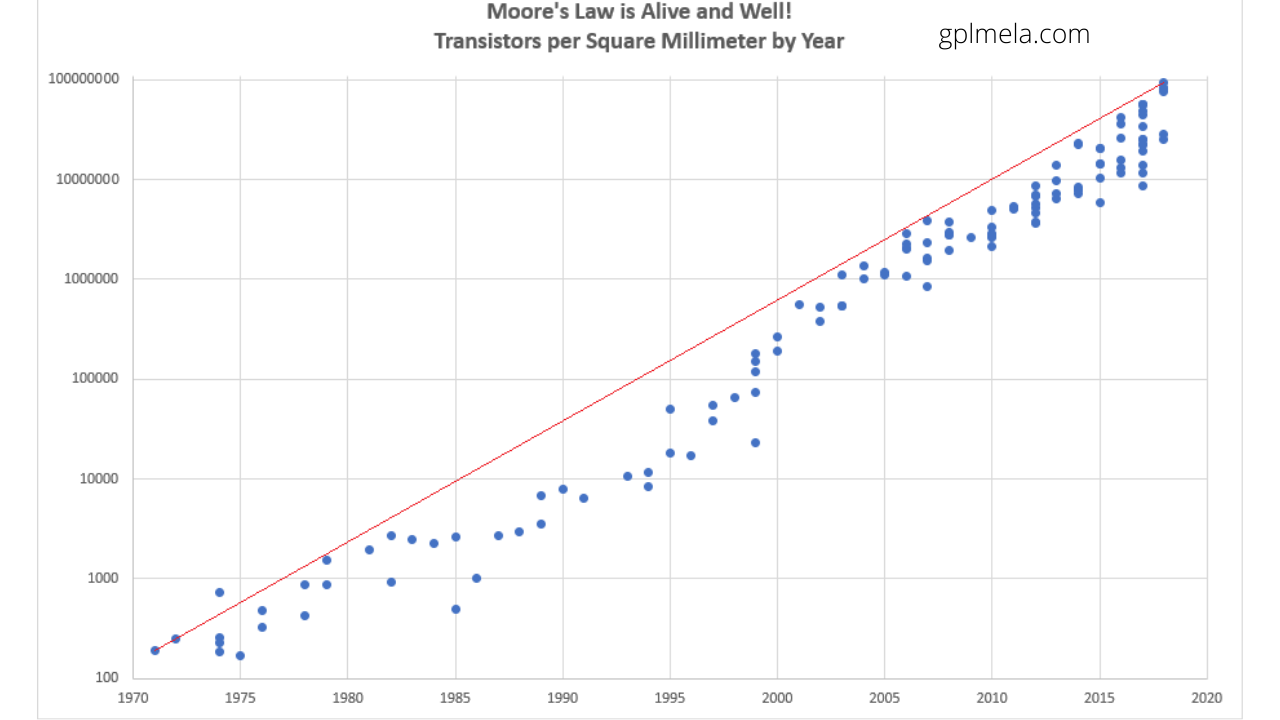
मूर का नियम, गॉर्डन मूर के नाम पर, ऐतिहासिक पैटर्न के माध्यम से टिप्पणी और प्रक्षेपण हैं कि अंतर्निर्मित सर्किट में ट्रांजिस्टर की विविधता, और इस तथ्य के कारण विस्तार द्वारा प्रोसेसर, हर दो साल मे दोगुना हो जाता हैं। संसाधको की प्रगति ने मूर के विधान को सावधानी से अपनाया है।
Types
सेंट्रल प्रोसेसिंग यूनिट (सीपीयू) अधिकांश कंप्यूटर सिस्टम मे पहले प्रोसेसर है। वे केवल कुछ डोमेन-विशिष्ट कर्तव्यो की तुलना मे सभी प्रकार के बुनियादी कंप्यूटिंग कर्तव्यो से निपटने के लिए डिज़ाइन किए गए है। यदि ज्यादातर वॉन न्यूमैन वास्तुकला पर आधारित है, तो उनमे कम से कम एक नियंत्रण इकाई (सीयू), एक अंकगणितीय तर्क इकाई (एएलयू), और प्रोसेसर रजिस्टर शामिल हैं। निरीक्षण मे, निजी कंप्यूटर सिस्टम मे सीपीयू आमतौर पर अतिरिक्त रूप से मदरबोर्ड के माध्यम से, एक मुख्य मेमोरी वित्तीय संस्थान, हार्ड ड्राइव या अन्य स्थायी भंडारण, और बाह्य उपकरणो, एक कीबोर्ड और माउस के बराबर से संबंधित होते है।
ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) बहुत सारे कंप्यूटर सिस्टम मे चालू है और रैखिक बीजगणित के साथ कंप्यूटर ग्राफिक्स संचालन को प्रभावी ढंग से करने के लिए डिज़ाइन किए गए है। वे बेहद समानांतर है, और सीपीयू सामान्य रूप से सीरियल प्रोसेसिंग की आवश्यकता वाले कर्तव्यो पर उच्च प्रदर्शन करते है। हालाँकि GPU को शुरू में ग्राफिक्स मे उपयोग करने के लिए बनाया गया हैं, समय के साथ उनके सॉफ़्टवेयर डोमेन का विस्तार हुआ हैं, और इसलिए वे मशीन सीखने के लिए {हार्डवेयर} का एक आवश्यक टुकड़ा बन गए हैं।
मशीन अध्ययन के लिए विशेषीकृत कई प्रकार के प्रोसेसर है। ये एआई त्वरक (अक्सर तंत्रिका प्रसंस्करण इकाइयों, या एनपीयू के रूप में जाना जाता है) के वर्ग से नीचे आते हैं और दृष्टि प्रसंस्करण इकाइयो (वीपीयू) और Google की टेंसर प्रोसेसिंग यूनिट (टीपीयू) को शामिल करते हैं।
ऑडियो बनाने और प्रोसेस करने के लिए साउंड चिप्स और साउंड कार्ड का उपयोग किया जाता है। डिजिटल सिग्नल प्रोसेसर (डीएसपी) डिजिटल संकेतकों को संसाधित करने के लिए डिज़ाइन किए गए हैं। इमेज सिग्नल प्रोसेसर विशेष रूप से तस्वीरों को संसाधित करने के लिए विशेषीकृत डीएसपी हैं।
भौतिकी प्रसंस्करण इकाइयों (पीपीयू) का निर्माण भौतिकी से संबंधित गणनाओं को प्रभावी ढंग से करने के लिए किया जाता है, खासकर वीडियो वीडियो गेम में।
फील्ड-प्रोग्रामेबल गेट एरेज़ (FPGAs) विशेष सर्किट हैं जिन्हें विभिन्न कार्यों के लिए पुन: कॉन्फ़िगर किया जा सकता है, जो कि पूरे निर्माण में एक विशिष्ट सॉफ़्टवेयर क्षेत्र में बंद होने के बजाय काफी है।
सिनर्जिस्टिक प्रोसेसिंग एलिमेंट या यूनिट (एसपीई या एसपीयू) सेल माइक्रोप्रोसेसर के भीतर एक तत्व है।
ज्यादातर पूरी तरह से अलग सर्किट तकनीक पर आधारित प्रोसेसर विकसित किए गए हैं। एक उदाहरण क्वांटम प्रोसेसर है, जो क्वांटम भौतिकी का उपयोग एल्गोरिदम को अनुमति देने के लिए करता है जो शास्त्रीय कंप्यूटर सिस्टम (ये पारंपरिक सर्किटरी का उपयोग करते हुए) पर अप्राप्य हो सकते है । एक अन्य उदाहरण फोटोनिक प्रोसेसर है, जो अर्धचालक इलेक्ट्रॉनिक्स के विकल्प के रूप में संगणना करने के लिए माइल्ड का उपयोग करता है। प्रोसेसर मे निहित लेज़रो द्वारा उत्पादित माइल्ड सेंसिंग फोटोडेटेक्टर्स द्वारा प्रसंस्करण पूरा किया जाता है।
Central processing unit (सेंट्रल प्रोसेसिंग यूनिट)
एक केंद्रीय प्रसंस्करण इकाई (सीपीयू), जिसे अतिरिक्त रूप से केंद्रीय प्रोसेसर, अग्रणी प्रोसेसर या केवल प्रोसेसर के रूप में जाना जाता है, एक इलेक्ट्रॉनिक सर्किटरी है जो कंप्यूटर प्रोग्राम से जुड़े निर्देशों को निष्पादित करती है। सीपीयू इस प्रणाली में निर्देशों द्वारा निर्दिष्ट प्राथमिक अंकगणित, तर्क, नियंत्रण और इनपुट/आउटपुट (I/O) संचालन करता है। यह मुख्य मेमोरी और I/O सर्किटरी, [1] और ग्राफिक्स प्रोसेसिंग यूनिट्स (GPU) के तुलनीय विशेष प्रोसेसर की तुलना में बाहरी भागो के साथ विरोधाभासी है।
सीपीयू के प्रकार, डिजाइन और कार्यान्वयन मे समय के साथ बदलाव आया है, हालांकि उनका प्रारंभिक संचालन लगभग अपरिवर्तित रहता है। एक सीपीयू के प्रमुख भाग अंकगणित-तर्क इकाई (एएलयू) को शामिल करते हैं जो अंकगणित और तर्क संचालन करता है, प्रोसेसर रजिस्टर जो एएलयू और खुदरा विक्रेता को एएलयू संचालन के परिणामो की पेशकश करता है, और एक नियंत्रण इकाई जो भ्रूण (स्मरण से) को व्यवस्थित करती है, एएलयू, रजिस्टरों और विभिन्न भागो के समन्वित संचालन को निर्देशित करके डिकोडिंग और निर्देशो का निष्पादन।
अधिकांश ट्रेंडी सीपीयू एकीकृत सर्किट (आईसी) माइक्रोप्रोसेसरों पर लागू होते हैं, जिसमें एक आईसी चिप पर कई सीपीयू होते हैं। कई सीपीयू के साथ माइक्रोप्रोसेसर चिप्स मल्टी-कोर प्रोसेसर हैं। विशेष व्यक्ति शारीरिक सीपीयू, प्रोसेसर कोर, को भी आगे डिजिटल या तार्किक सीपीयू बनाने के लिए बहु-थ्रेडेड किया जा सकता है।[2]
एक आईसी जिसमें एक सीपीयू शामिल है, में अतिरिक्त रूप से मेमोरी, परिधीय इंटरफेस और एक पीसी के विभिन्न हिस्से शामिल हो सकते हैं; ऐसे बिल्ट-इन गैजेट्स को माइक्रोकंट्रोलर या चिप पर सिस्टम (SoC) के रूप में जाना जाता है।
ऐरे प्रोसेसर या वेक्टर प्रोसेसर में कई प्रोसेसर होते हैं जो समानांतर में कार्य करते हैं, बिना किसी इकाई के केंद्रीय विचार के। वर्चुअल सीपीयू डायनेमिक एग्रीगेटेड कम्प्यूटेशनल सोर्स का एक एब्स्ट्रैक्शन है।

History (इतिहास)
प्रारंभिक कंप्यूटर सिस्टम जैसे कि ENIAC को पूरी तरह से अलग-अलग कर्तव्यो को पूरा करने के लिए शारीरिक रूप से रीवायर करने की आवश्यकता थी, जिसने इन मशीनो को “फिक्स्ड-प्रोग्राम कंप्यूटर” के रूप मे संदर्भित किया। “सेंट्रल प्रोसेसिंग यूनिट” समय अवधि 1955 से ही प्रयोग मे है। चूंकि समय अवधि “सीपीयू” को आमतौर पर सॉफ्टवेयर (लैपटॉप प्रोग्राम) निष्पादन के लिए एक उपकरण के रूप में उल्लिखित किया जाता है, इसलिए शुरुआती इकाइयां जिन्हे सीपीयू के रूप में संदर्भित किया जा सकता है, संग्रहीत-प्रोग्राम कंप्यूटर की उपस्थिति के साथ यहां आए।
जे. प्रेस्पर एकर्ट और जॉन विलियम मौचली के ENIAC के डिजाइन में स्टोर-प्रोग्राम लैपटॉप का विचार पहले से ही मौजूद था, लेकिन शुरुआत मे इसे छोड़ दिया गया था ताकि इसे जल्द से जल्द पूरा किया जा सके। 30 जून, 1945 को, ENIAC के बनने से पहले, गणितज्ञ जॉन वॉन न्यूमैन ने EDVAC पर एक रिपोर्ट का पहला मसौदा शीर्षक से पेपर वितरित किया।
यह एक संग्रहीत-प्रोग्राम लैपटॉप की परिभाषा थी जिसे अंततः अगस्त 1949 में पूरा किया जाएगा। EDVAC को विभिन्न किस्मो के एक निश्चित किस्म के दिशा-निर्देश (या संचालन) करने के लिए डिज़ाइन किया गया था।
महत्वपूर्ण रूप से, ईडीवीएसी के लिए लिखे गए पैकेजो को पीसी की शारीरिक वायरिंग द्वारा निर्दिष्ट की तुलना मे उच्च गति वाली कंप्यूटर मेमोरी मे सहेजा जाना था। इसने ENIAC की एक चरम सीमा को पार कर लिया, जो एक नया काम करने के लिए पीसी को फिर से कॉन्फ़िगर करने के लिए आवश्यक प्रशंसनीय प्रयास और समय था।
वॉन न्यूमैन के डिजाइन के साथ, यह प्रणाली जिसे ईडीवीएसी ने चलाया था, संभवतः स्मृति की सामग्री को बदलकर संशोधित किया जा सकता था। ईडीवीएसी, फिर भी, प्राथमिक संग्रहित-प्रोग्राम लैपटॉप नहीं था; मैनचेस्टर बेबी, एक छोटे पैमाने का प्रायोगिक स्टोर-प्रोग्राम लैपटॉप, ने अपना पहला प्रोग्राम 21 जून 1948 को चलाया और मैनचेस्टर मार्क 1 ने 16-17 जून 1949 की शाम को अपना पहला कार्यक्रम चलाया।
प्रारंभिक सीपीयू को अनुकूलित डिजाइन के रूप में इस्तेमाल किया गया था जो आधे बड़े और विशिष्ट रूप से विशिष्ट लैपटॉप के रूप मे उपयोग किया जाता था। हालांकि, एक विशिष्ट सॉफ्टवेयर के लिए अनुकूलित सीपीयू को डिजाइन करने की इस पद्धति ने बड़े पैमाने पर उत्पादित बहुउद्देश्यीय प्रोसेसर की घटना के लिए बड़े पैमाने पर रणनीति दी है।
यह मानकीकरण असतत ट्रांजिस्टर मेनफ्रेम और मिनीकंप्यूटर की अवधि के भीतर शुरू हुआ और एकीकृत सर्किट (आईसी) के लोकप्रिय होने के साथ तेजी से बढ़ा है। आईसी ने अधिक से अधिक जटिल सीपीयू को नैनोमीटर के क्रम पर सहनशीलता के लिए डिजाइन और निर्मित करने की अनुमति दी है।
सीपीयू के लघुकरण और मानकीकरण दोनों ने समर्पित कंप्यूटिंग मशीनों के प्रतिबंधित सॉफ्टवेयर से काफी पहले फैशनेबल जीवन में डिजिटल इकाइयों की उपस्थिति को बढ़ा दिया है। आधुनिक माइक्रोप्रोसेसर कारों[15] से लेकर सेलफोन, और आमतौर पर खिलौनों में भी डिजिटल इकाइयों में प्रतीत होते हैं।
जबकि वॉन न्यूमैन को अक्सर ईडीवीएसी के अपने डिजाइन के कारण संग्रहित-प्रोग्राम लैपटॉप के डिजाइन का श्रेय दिया जाता है, और डिजाइन को वॉन न्यूमैन आर्किटेक्चर के रूप में संदर्भित किया जाने लगा, जबकि उनके पहले के अन्य, कोनराड ज़ूस से मिलते-जुलते थे, ने सलाह दी थी और लागू किया था तुलनीय अवधारणाएं। हार्वर्ड मार्क I
की तथाकथित हार्वर्ड वास्तुकला, जिसे ईडीवीएसी से पहले पूरा किया गया था, ने अतिरिक्त रूप से डिजिटल स्मृति की तुलना में छिद्रित पेपर टेप का उपयोग करते हुए एक संग्रहीत-कार्यक्रम डिजाइन का उपयोग किया। वॉन न्यूमैन और हार्वर्ड आर्किटेक्चर के बीच मुख्य अंतर यह है कि उत्तरार्द्ध सीपीयू दिशाओं और सूचनाओं के भंडारण और उपचार को अलग करता है, जबकि पिछला प्रत्येक के लिए समान स्मृति क्षेत्र का उपयोग करता है।
अधिकांश फैशनेबल सीपीयू मुख्य रूप से डिजाइन में वॉन न्यूमैन हैं, हालांकि हार्वर्ड संरचना वाले सीपीयू को ठीक से देखा जाता है, विशेष रूप से एम्बेडेड उद्देश्यों में; उदाहरण के तौर पर, एटमेल एवीआर माइक्रोकंट्रोलर हार्वर्ड स्ट्रक्चर प्रोसेसर हैं।
रिले और वैक्यूम ट्यूब (थर्मिओनिक ट्यूब) का उपयोग आमतौर पर स्विचिंग घटकों के रूप में किया जाता था; एक सहायक लैपटॉप के लिए 1000 या दसियों 1000 स्विचिंग इकाइयों की आवश्यकता होती है। सिस्टम की कुल गति स्विच की गति पर निर्भर करती है। ईडीवीएसी से मिलते-जुलते वैक्यूम-ट्यूब कंप्यूटर विफलताओं के बीच सामान्य आठ घंटे तक चलते थे, जबकि (धीमे, हालांकि पहले) हार्वर्ड मार्क I
की तरह ही रिले कंप्यूटर सिस्टम शायद ही कभी विफल हुए हों। टिप में, ट्यूब-आधारित सीपीयू प्रमुख हो गए क्योंकि कई गति लाभों के परिणामस्वरूप आमतौर पर विश्वसनीयता के मुद्दों से आगे निकल गए। उन शुरुआती सिंक्रोनस सीपीयू में से अधिकांश फैशनेबल माइक्रोइलेक्ट्रॉनिक डिजाइनो की तुलना मे कम घड़ी दरों पर चलते थे।
100 किलोहर्ट्ज़ से 4 मेगाहर्ट्ज तक शुरू होने वाली घड़ी संकेत आवृत्तियां वर्तमान में काफी सामान्य थीं, जो बड़े पैमाने पर उन स्विचिंग इकाइयों की गति से प्रतिबंधित थीं जिनके साथ उनका निर्माण किया गया था।
ट्रांजिस्टर सीपीयू
सीपीयू की डिजाइन जटिलता कई अनुप्रयुक्त विज्ञानो के रूप में बढ़ी, जिससे छोटी और अधिक भरोसेमंद डिजिटल इकाइयो के निर्माण मे मदद मिली। इस तरह का पहला सुधार ट्रांजिस्टर के आने से हुआ।
उन्नीस पचास और उन्नीस साठ के दशक मे ट्रांजिस्टरीकृत सीपीयू को अब वैक्यूम ट्यूब और रिले जैसे बोझिल, अविश्वसनीय और नाजुक स्विचिंग भागो से निर्मित करने की आवश्यकता नहीं थी। इस सुधार के साथ, असतत (विशेष व्यक्ति) तत्वो वाले एक या कई मुद्रित सर्किट बोर्डों पर अतिरिक्त जटिल और भरोसेमंद सीपीयू का निर्माण किया गया है।
1964 मे, आईबीएम ने अपने आईबीएम सिस्टम/360 पीसी संरचना को लॉन्च किया जिसका उपयोग पूरी तरह से अलग वेग और दक्षता के साथ समान पैकेजों को संचालित करने मे सक्षम कंप्यूटर सिस्टम के अनुक्रम में किया गया था। यह ऐसे समय में महत्वपूर्ण था जब अधिकांश डिजिटल कंप्यूटर सिस्टम एक-दूसरे के साथ असंगत रहे है, यहां तक कि ये एक ही निर्माता द्वारा बनाए गए है।
इस सुधार को सुविधाजनक बनाने के लिए, आईबीएम ने एक माइक्रोप्रोग्राम (आमतौर पर “माइक्रोकोड” के रूप मे जाना जाता है) के विचार का इस्तेमाल किया, जो फिर भी ट्रेंडी सीपीयू में व्यापक उपयोग को देखता है। सिस्टम/360 संरचना इतनी फैशनेबल थी कि यह लंबे समय तक मेनफ्रेम कंप्यूटर बाज़ार पर हावी रही और एक ऐसी विरासत छोड़ी जो अभी भी आईबीएम zSeries की तरह तुलनीय ट्रेंडी कंप्यूटर सिस्टम द्वारा जारी है।
1965 में, डिजिटल उपकरण निगम (DEC) ने वैज्ञानिक और विश्लेषण बाजारों, PDP-8 के उद्देश्य से एक अन्य प्रभावशाली पीसी लॉन्च किया।
फुजित्सु बोर्ड SPARC64 VIIIfx प्रोसेसर के साथ
ट्रांजिस्टर-आधारित कंप्यूटर सिस्टम के अपने पूर्ववर्तियो की तुलना मे कई अलग-अलग लाभ थे। उच्च विश्वसनीयता को सुविधाजनक बनाने और ऊर्जा की खपत को कम करने के अलावा, ट्रांजिस्टर ने अतिरिक्त रूप से सीपीयू को एक ट्यूब या रिले की तुलना मे ट्रांजिस्टर के त्वरित स्विचिंग समय के कारण बहुत अधिक गति से कार्य करने की अनुमति दी।
स्विचिंग भागो की उन्नत विश्वसनीयता और नाटकीय रूप से ऊंचा वेग (जो इस समय तक लगभग पूरी तरह से ट्रांजिस्टर रहे है); इस पूरे युग में सीपीयू क्लॉक चार्ज दसियो मेगाहर्ट्ज़ के भीतर आसानी से प्राप्त कर लिया गया है। [35] इसके अतिरिक्त, जबकि असतत ट्रांजिस्टर और आईसी सीपीयू भारी उपयोग मे है, नए उच्च-प्रदर्शन डिजाइन जैसे एकल निर्देश, एकाधिक डेटा (सिम) वेक्टर प्रोसेसर दिखाई देने लगे।
इन प्रारंभिक प्रयोगात्मक डिजाइनो ने बाद मे क्रे इंक और फुजित्सु लिमिटेड द्वारा बनाए गए विशेष सुपर कंप्यूटरो की अवधि को जन्म दिया।

छोटे पैमाने पर एकीकरण सीपीयू
इस युग के दौरान, एक कॉम्पैक्ट क्षेत्र मे कई इंटरकनेक्टेड ट्रांजिस्टर बनाने का एक तरीका विकसित किया गया था। एकीकृत सर्किट (आईसी) ने एक अर्धचालक-आधारित डाई, या “चिप” पर बहुत सारे ट्रांजिस्टर का निर्माण करने की अनुमति दी। सबसे पहले, एनओआर गेट्स के समान केवल बहुत ही मौलिक गैर-विशिष्ट डिजिटल सर्किट को आईसी मे छोटा किया गया है।
ज्यादातर इन “बिल्डिंग ब्लॉक” IC पर आधारित CPU को आमतौर पर “स्मॉल-स्केल इंटीग्रेशन” (SSI) गैजेट्स के रूप मे जाना जाता हैं। एसएसआई आईसी, अपोलो गाइडेंस कंप्यूटर के भीतर इस्तेमाल होने वाले लोगो के समान, अक्सर कुछ दर्जन ट्रांजिस्टर होते है। SSI IC से पूरे CPU के निर्माण के लिए 1000 विशेष व्यक्ति चिप्स की आवश्यकता होती हैं, लेकिन फिर भी पहले के असतत ट्रांजिस्टर डिजाइनो की तुलना मे बहुत कम क्षेत्र और ऊर्जा की खपत होती है।
IBM का सिस्टम/370, सिस्टम/360 का फॉलो-ऑन, सॉलिड लॉजिक टेक्नोलॉजी डिस्क्रीट-ट्रांजिस्टर मॉड्यूल की तुलना मे SSI IC का काफी उपयोग करता है।DEC के PDP-8/I और KI10 PDP-10 को भी PDP-8 और PDP-10 द्वारा उपयोग किए जाने वाले व्यक्ति ट्रांजिस्टर से SSI IC में स्विच किया गया, और उनकी असाधारण रूप से फैशनेबल PDP-11 लाइन शुरू में SSI IC के साथ बनाई गई थी, लेकिन थी अंत मे एलएसआई भागो के साथ लागू किया गया जैसे ही ये समझदार हो गए|
बड़े पैमाने पर एकीकरण सीपीयू
चूंकि माइक्रोइलेक्ट्रॉनिक तकनीक बेहतर है, इसलिए आईसी पर ट्रांजिस्टर की बढ़ती संख्या को तैनात किया गया था, जिससे पूरे सीपीयू के लिए विशिष्ट व्यक्ति आईसी की संख्या कम हो गई थी। MSI और LSI ICs एलिवेटेड ट्रांजिस्टर काउंट एक पूरे गुच्छा तक, और फिर सैकड़ो। 1968 तक, एक संपूर्ण CPU के निर्माण के लिए आवश्यक IC की विविधता को आठ अलग-अलग प्रकार के 24 IC तक कम कर दिया गया था,
जिसमें प्रत्येक IC मे लगभग 1000 MOSFETs थे। अपने एसएसआई और एमएसआई पूर्ववर्तियों के साथ स्पष्ट अंतर मे, पीडीपी-11 के प्राथमिक एलएसआई कार्यान्वयन में केवल 4 एलएसआई अंतर्निर्मित सर्किट से बना एक सीपीयू शामिल था।
Microprocessors
ली बॉयसेल ने 1967 के “घोषणापत्र” के साथ प्रभावशाली लेख छापे, जिसमें तुलनात्मक रूप से छोटी किस्म के बड़े पैमाने के एकीकरण सर्किट (LSI) से 32-बिट मेनफ्रेम पीसी के बराबर के निर्माण का सबसे अच्छा तरीका बताया गया। एलएसआई चिप्स के निर्माण की एकमात्र रणनीति, जो कि 100 या अधिक गेट वाले चिप्स हैं, उन्हें धातु-ऑक्साइड-सेमीकंडक्टर (एमओएस) सेमीकंडक्टर निर्माण प्रक्रिया (पीएमओएस लॉजिक, एनएमओएस लॉजिक, या सीएमओएस लॉजिक दोनों) का उपयोग करके बनाना था। हालांकि, कुछ कंपनियों ने द्विध्रुवी ट्रांजिस्टर-ट्रांजिस्टर लॉजिक (टीटीएल) चिप्स से प्रोसेसर का निर्माण जारी रखा क्योंकि द्विध्रुवी जंक्शन ट्रांजिस्टर उन्नीस सत्तर के दशक तक एमओएस चिप्स से तेज थे (डेटापॉइंट की तुलना में कुछ कंपनियों ने प्रोसेसर का निर्माण जारी रखा था) टीटीएल चिप्स के शुरुआती अस्सी के दशक तक)। साठ के दशक में, MOS IC धीमे थे और शुरू में केवल उन उद्देश्यों में मददगार माने जाते थे जिनमें कम ऊर्जा की आवश्यकता होती थी। 1968 में फेयरचाइल्ड सेमीकंडक्टर में फेडरिको फागिन द्वारा सिलिकॉन-गेट एमओएस तकनीक की घटना के बाद, एमओएस आईसी ने बड़े पैमाने पर द्विध्रुवी टीटीएल को उन्नीसवीं सत्तर के दशक की शुरुआत में सामान्य चिप जानकारी के रूप में बदल दिया।
प्राथमिक व्यावसायिक रूप से प्राप्य माइक्रोप्रोसेसर, 1971 में इंटेल 4004, और 1974 में बड़े पैमाने पर उपयोग किए जाने वाले प्राथमिक माइक्रोप्रोसेसर, इंटेल 8080 की शुरुआत के बाद से, सीपीयू के इस वर्ग ने सभी विभिन्न केंद्रीय प्रसंस्करण इकाई कार्यान्वयन रणनीतियों को पूरी तरह से पीछे छोड़ दिया है। उस समय के मेनफ्रेम और मिनीकंप्यूटर उत्पादकों ने अपने पुराने कंप्यूटर आर्किटेक्चर को बेहतर बनाने के लिए मालिकाना आईसी सुधार अनुप्रयोगों को लॉन्च किया, और अंत में निर्देश सेट उपयुक्त माइक्रोप्रोसेसरों का उत्पादन किया जो उनके पुराने {हार्डवेयर} और सॉफ्टवेयर प्रोग्राम के साथ पिछड़े-संगत थे। कभी-कभी मौजूद पर्सनल कंप्यूटर के आगमन और अंतिम सफलता के साथ संयुक्त, समय अवधि सीपीयू अब लगभग पूरी तरह से माइक्रोप्रोसेसरों के लिए उपयोग किया जाता है। एक ही प्रोसेसिंग चिप में कई सीपीयू (दिखाए गए कोर) मिश्रित होंगे।
सीपीयू की पिछली पीढ़ियों को कई सर्किट बोर्डों पर असतत घटकों और कुछ छोटे एकीकृत सर्किट (आईसी) के रूप में लागू किया गया था। माइक्रोप्रोसेसर, वैकल्पिक रूप से, सीपीयू हैं जो वास्तव में छोटी किस्म के आईसी पर निर्मित होते हैं; आम तौर पर केवल एक। कुल छोटे सीपीयू आयाम, एक ही पासे पर लागू होने के कारण, गेट परजीवी समाई जैसे शारीरिक तत्वों के कारण जल्द ही स्विचिंग समय का मतलब है। इसने सिंक्रोनस माइक्रोप्रोसेसरों को दसियों मेगाहर्ट्ज़ से लेकर कई गीगाहर्ट्ज़ तक घड़ी के चार्ज रखने की अनुमति दी है। इसके अतिरिक्त, एक आईसी पर अत्यधिक छोटे ट्रांजिस्टर को इकट्ठा करने के लचीलेपन ने एक ही सीपीयू में ट्रांजिस्टर की जटिलता और विविधता को कई गुना बढ़ा दिया है। यह व्यापक रूप से देखा गया विकास मूर के कानून द्वारा वर्णित है, जिसने 2016 तक सीपीयू (और विभिन्न आईसी) जटिलता के विस्तार का एक उचित रूप से सही भविष्यवक्ता होने की पुष्टि की थी।

जबकि जटिलता, आयाम, विकास और सामान्य प्रकार के सीपीयू में 1950 के बाद से काफी बदलाव आया है, मौलिक डिजाइन और प्रदर्शन मे किसी भी तरह से बहुत अधिक बदलाव नहीं हुआ है। इस समय लगभग सभी बार-बार आने वाले सीपीयू को बहुत सटीक रूप से वॉन न्यूमैन स्टोर-प्रोग्राम मशीन के रूप मे वर्णित किया जाएगा। जैसा कि मूर का विनियमन अब नहीं है, अंतर्निर्मित सर्किट ट्रांजिस्टर विशेषज्ञता की सीमाओ के संबंध मे मुद्दे उत्पन्न हुए हैं। इलेक्ट्रॉनिक फाटकों का अत्यधिक लघुकरण इलेक्ट्रोमाइग्रेशन और सबथ्रेशोल्ड लीकेज जैसी घटनाओं के परिणामो को कही अधिक महत्वपूर्ण मे बदलने के लिए प्रेरित कर रहा है। ये नए मुद्दे शोधकर्ताओ को कंप्यूटिंग की नई रणनीतियो का विश्लेषण करने के लिए प्रेरित करने वाले कई तत्वो मे से है, क्योकि क्वांटम कंप्यूटर, समानांतरवाद के उपयोग को व्यापक बनाने और शास्त्रीय वॉन न्यूमैन पुतले की उपयोगिता तक पहुंचने वाली विभिन्न रणनीतियों के अलावा।
Operation
अधिकांश सीपीयू का मौलिक संचालन, चाहे वे किसी भी भौतिक रूप मे हो, संग्रहीत निर्देशो के अनुक्रम को निष्पादित करना हैं जिसे प्रोग्राम कहा जाता हैं । निष्पादित किए जाने वाले निर्देश किसी प्रकार की कंप्यूटर मेमोरी मे रखे जाते है। लगभग सभी सीपीयू अपने संचालन मे चरणो को लाने, डिकोड करने और निष्पादित करने का पालन करते हैं, जिन्हें सामूहिक रूप से निर्देश चक्र के रूप मे जाना जाता है।
एक निर्देश के निष्पादन के बाद, पूरी प्रक्रिया दोहराई जाती है, अगले निर्देश चक्र के साथ सामान्य रूप से प्रोग्राम काउंटर मे बढ़े हुए मूल्य के कारण अगला-इन-सीक्वेस निर्देश प्राप्त होता है। यदि एक कूद निर्देश निष्पादित किया गया था, तो प्रोग्राम काउंटर को उस निर्देश के पते को शामिल करने के लिए संशोधित किया जाएगा जिसे कूद गया था और प्रोग्राम निष्पादन सामान्य रूप से जारी रहता है।
अधिक जटिल सीपीयू मे, एक साथ कई निर्देश प्राप्त किए जा सकते है, डिकोड किए जा सकते है और निष्पादित किए जा सकते है। यह खंड वर्णन करता हैं कि आम तौर पर “क्लासिक आरआईएससी पाइपलाइन” के रूप में जाना जाता हैं, जो कई इलेक्ट्रॉनिक उपकरणो (अक्सर माइक्रोकंट्रोलर कहा जाता हैं) मे उपयोग किए जाने वाले साधारण सीपीयू मे काफी आम है। यह काफी हद तक सीपीयू कैश की महत्वपूर्ण भूमिका की उपेक्षा करता हैं, और इसलिए पाइपलाइन का एक्सेस चरण।
कुछ निर्देश सीधे परिणाम डेटा उत्पन्न करने के बजाय प्रोग्राम काउंटर में हेरफेर करते हैं; इस तरह के निर्देशो को आम तौर पर “कूद” कहा जाता है और लूप, सशर्त प्रोग्राम निष्पादन (सशर्त कूद के उपयोग के माध्यम से), और कार्यो के अस्तित्व जैसे प्रोग्राम व्यवहार की सुविधा प्रदान करता हैं। कुछ प्रोसेसर मे, कुछ अन्य निर्देश बिट्स की स्थिति को एक मे बदलते है। “झंडे” रजिस्टर।
इन झंडो का उपयोग किसी कार्यक्रम के व्यवहार को प्रभावित करने के लिए किया जा सकता हैं, क्योकि वे अक्सर विभिन्न कार्यो के परिणाम का संकेत देते है। उदाहरण के लिए, ऐसे प्रोसेसर मे एक “तुलना” निर्देश दो मानो का मूल्यांकन करता हैं और फ़्लैग रजिस्टर मे बिट्स को सेट या साफ़ करता हैं यह इंगित करने के लिए कि कौन सा बड़ा हैं या क्या वे बराबर है; इन झंडो मे से एक का उपयोग प्रोग्राम प्रवाह को निर्धारित करने के लिए बाद मे कूदने के निर्देश द्वारा किया जा सकता हैं।
Fetch
पहला कदम, फ़ेच, प्रोग्राम मेमोरी से एक निर्देश (जो एक संख्या या संख्याओ के अनुक्रम द्वारा दर्शाया गया हैं) को पुनः प्राप्त करना शामिल हैं। प्रोग्राम मेमोरी मे निर्देश का स्थान (पता) प्रोग्राम काउंटर (पीसी; जिसे इंटेल x86 माइक्रोप्रोसेसरो मे “इंस्ट्रक्शन पॉइंटर” कहा जाता हैं) द्वारा निर्धारित किया जाता हैं, जो एक नंबर को स्टोर करता हैं जो अगले निर्देश के पते की पहचान करता हैं। एक निर्देश प्राप्त होने के बाद, पीसी को निर्देश की लंबाई से बढ़ाया जाता हैं ताकि इसमे अनुक्रम मे अगले निर्देश का पता होगा। अक्सर, प्राप्त किए जाने वाले निर्देश को अपेक्षाकृत धीमी मेमोरी से पुनर्प्राप्त किया जाना चाहिए, जिससे निर्देश के वापस आने की प्रतीक्षा करते हुए सीपीयू ठप हो जाता हैं। कैश और पाइपलाइन आर्किटेक्चर (नीचे देखे) द्वारा आधुनिक प्रोसेसर मे इस मुद्दे को काफी हद तक संबोधित किया गया हैं।
व्याख्या करना
सीपीयू मेमोरी से जो निर्देश प्राप्त करता हैं वह निर्धारित करता हैं कि सीपीयू क्या करेगा। डिकोड चरण मे, निर्देश डिकोडर के रूप मे ज्ञात बाइनरी डिकोडर सर्किटरी द्वारा निष्पादित, निर्देश को सिग्नल मे परिवर्तित किया जाता हैं जो सीपीयू के अन्य भागो को नियंत्रित करता है।
निष्पादित
फ़ेच और डीकोड चरणों के बाद, निष्पादन चरण किया जाता है। सीपीयू संरचना के आधार पर, इसमें एकल गति या क्रियाओं का क्रम शामिल होगा। प्रत्येक गति के दौरान, प्रबंधन अलर्ट सीपीयू के कई घटकों को विद्युत रूप से अनुमति देता है या अक्षम करता है ताकि वे निर्दिष्ट ऑपरेशन के सभी या एक हिस्से को पूरा कर सकें। गति तब पूरी होती है, कभी-कभी घड़ी की नाड़ी के जवाब में। बहुत बार परिणाम अगले निर्देशों द्वारा तेजी से प्रवेश के लिए एक आंतरिक सीपीयू रजिस्टर में लिखे जाते हैं। अन्य मामलों में परिणाम धीमी गति से लिखे जा सकते हैं, हालांकि सस्ती और बेहतर क्षमता वाली मुख्य मेमोरी।
उदाहरण के लिए, यदि एक अतिरिक्त निर्देश निष्पादित किया जाना हैं, तो ऑपरेड (संख्याओ को संक्षेप मे) वाले रजिस्टर सक्रिय होते है, जैसे कि अंकगणितीय तर्क इकाई (एएलयू) के घटक जो अतिरिक्त करते है। जब क्लॉक पल्स होता है, तो ऑपरेंड आपूर्ति रजिस्टर से ALU में चले जाते है, और योग इसके आउटपुट पर लगता हैं। बाद की घड़ी की दालो पर, विभिन्न भागो को आउटपुट (ऑपरेशन का योग) को भंडारण (जैसे, एक रजिस्टर या स्मरण) मे पैंतरेबाज़ी करने के लिए सक्षम (और अक्षम) किया जाता हैं। यदि आगामी योग बहुत विशाल हैं (यानी, यह ALU के आउटपुट वाक्यांश आयाम से बड़ा हैं), तो एक अंकगणितीय अतिप्रवाह ध्वज सेट होने की संभावना हैं, जो निम्नलिखित ऑपरेशन को प्रभावित करेगा।
संरचना और कार्यान्वयन
सीपीयू के सर्किटरी मे हार्डवायर्ड प्राथमिक संचालन का एक सेट हैं जिसे संभवतः किया जाएगा, जिसे निर्देश सेट के रूप में जाना जाता हैं। उदाहरण के लिए, इस तरह के संचालन मे दो संख्याओ को शामिल करना या घटाना, दो संख्याओ का मूल्यांकन करना, या किसी कार्यक्रम के एक अद्वितीय भाग मे छलांग लगाना शामिल हो सकता हैं। प्रत्येक निर्देश को बिट्स के एक विलक्षण मिश्रण द्वारा दर्शाया जाता हैं, जिसे अक्सर मशीन भाषा ओपकोड के रूप मे जाना जाता हैं। एक निर्देश को संसाधित करते समय, सीपीयू ओपकोड (एक बाइनरी डिकोडर के माध्यम से) को प्रबंधन संकेतको मे डिकोड करता हैं, जो सीपीयू की आदतो को व्यवस्थित करता हैं। एक संपूर्ण मशीन भाषा निर्देश मे एक ओपकोड होता हैं और, कई उदाहरणो मे, अतिरिक्त बिट्स जो ऑपरेशन के लिए तर्क निर्दिष्ट करते है (उदाहरण के लिए, एक अतिरिक्त ऑपरेशन के मामले मे संख्याओ को सम्मिलित किया जाना हैं)। जटिलता के पैमाने पर जाने पर, एक मशीन भाषा प्रोग्राम मशीन भाषा दिशाओ का एक सेट हैं जिसे सीपीयू निष्पादित करता हैं।
नियंत्रण विभाग
प्रबंधन इकाई (सीयू) सीपीयू का एक तत्व हैं जो प्रोसेसर के संचालन को निर्देशित करता हैं। यह पीसी की मेमोरी, अंकगणित और लॉजिक यूनिट को बताता हैं और प्रोसेसर को भेजे गए निर्देशो का जवाब देने के लिए एंटर और आउटपुट यूनिट्स को बताता हैं।
यह समय और प्रबंधन अलर्ट प्रदान करके विपरीत मॉडलो के संचालन को निर्देशित करता हैं। अधिकांश लैपटॉप परिसंपत्तियो का प्रबंधन सीयू द्वारा किया जाता हैं। यह सीपीयू और विपरीत इकाइयो के बीच ज्ञान की धारा को निर्देशित करता है। जॉन वॉन न्यूमैन ने वॉन न्यूमैन वास्तुकला के एक भाग के रूप मे प्रबंधन इकाई को शामिल किया। फैशनेबल लैपटॉप डिजाइनो मे, प्रबंधन इकाई आमतौर पर सीपीयू के एक हिस्से के अंदर होती हैं, इसकी कुल स्थिति और संचालन इसके परिचय के बाद से अपरिवर्तित रहता हैं.
अंकगणितीय तर्क इकाई
अंकगणितीय तर्क इकाई (एएलयू) पूरे प्रोसेसर मे एक डिजिटल सर्किट है जो पूर्णांक अंकगणितीय और बिटवाइज तर्क संचालन करता हैं। एएलयू के इनपुट सूचना वाक्यांश है जिन्हे संचालित किया जाना हैं (संचालन के रूप मे जाना जाता हैं), पहले के संचालन से स्थायी डेटा, और प्रबंधन इकाई से एक कोड यह दर्शाता हैं कि कौन सा ऑपरेशन करना है। निष्पादित किए जा रहे निर्देश के आधार पर, ऑपरेड आंतरिक सीपीयू रजिस्टरो या बाहरी स्मरण से आ सकते है, या वे एएलयू द्वारा ही उत्पन्न स्थिरांक हो सकते है।
Address generation unit
एड्रेस टेक्नोलॉजी यूनिट (एजीयू), जिसे आमतौर पर डील विद कंप्यूटेशन यूनिट (एसीयू) के रूप मे जाना जाता हैं,सीपीयू मे निहित एक निष्पादन इकाई हैं जो सीपीयू द्वारा मुख्य मेमोरी मे प्रवेश करने के लिए उपयोग किए गए पतो की गणना करता हैं। अलग-अलग सर्किटरी द्वारा निपटाए गए गणनाओ से निपटने के द्वारा, जो शेष सीपीयू के साथ समानांतर मे संचालित होता हैं, कई मशीन निर्देशो को निष्पादित करने के लिए आवश्यक सीपीयू चक्रो की संख्या को कम किया जा सकता हैं, जिससे दक्षता में वृद्धि हो सकती हैं।
मेमोरी मैनेजमेंट यूनिट (MMU)
कई माइक्रोप्रोसेसरो (स्मार्टफोन और डेस्कटॉप, लैपटॉप कंप्यूटर, सर्वर कंप्यूटर सिस्टम मे) मे एक स्मरण प्रशासन इकाई होती हैं, जो तार्किक पतो को शारीरिक रैम पतो में अनुवाद करती है, स्मृति सुरक्षा और पेजिंग कौशल प्रदान करती हैं, जो वर्चुअल मेमोरी के लिए सहायक होती हैं। सरल प्रोसेसर, विशेष रूप से माइक्रोकंट्रोलर, आमतौर पर एमएमयू को शामिल नही करते है।
कैश
सीपीयू कैश एक हार्डवेयर कैश हैं जिसका उपयोग कंप्यूटर की सेंट्रल प्रोसेसिंग यूनिट (सीपीयू) द्वारा मुख्य मेमोरी से डेटा प्रविष्टि के लिए विशिष्ट मूल्य (समय या शक्ति) को कम करने के लिए किया जाता हैं। एक कैश एक प्रोसेसर कोर के नजदीक एक छोटा, जल्द ही याद दिलाता हैं,
जो लगातार उपयोग किए जाने वाले महत्वपूर्ण मेमोरी स्थानो से जानकारी की प्रतियां स्टोर करता हैं। अधिकांश सीपीयू मे निर्देश और डेटा कैश के साथ अलग-अलग निष्पक्ष कैश होते है, जहां डेटा कैश को सामान्य रूप से अतिरिक्त कैश रेंज (एल 1, एल 2, एल 3, एल 4, आदि) के पदानुक्रम के रूप में व्यवस्थित किया जाता हैं।
Clock rate
अधिकांश सीपीयू सिंक्रोनस सर्किट होते है, जिसका अर्थ है कि वे अपने अनुक्रमिक संचालन को गति देने के लिए एक घड़ी संकेत का उपयोग करते है। घड़ी का चिन्ह एक बाहरी थरथरानवाला सर्किट द्वारा निर्मित होता हैं जो एक आवधिक वर्ग तरंग के प्रकार के भीतर हर सेकंड एक निरंतर किस्म की दाले उत्पन्न करता हैं। घड़ी की दालो की आवृत्ति उस गति को निर्धारित करती हैं जिस पर सीपीयू दिशाओ को निष्पादित करता हैं और, परिणामस्वरूप, घड़ी जितनी तेज होती हैं, सीपीयू हर सेकंड मे उतनी ही अतिरिक्त दिशाएं निष्पादित करता है ।
सीपीयू के सही संचालन की गारंटी के लिए, घड़ी का अंतराल सीपीयू के माध्यम से सभी संकेतको के प्रचार (स्थानांतरण) के लिए वांछित अधिकतम समय से अधिक लंबा हैं। घड़ी के अंतराल को सबसे खराब स्थिति के प्रसार विलंब से अच्छी तरह से ऊपर की कीमत पर सेट करने मे, यह पूरे सीपीयू को डिजाइन करने योग्य हैं और यह बढ़ते और गिरने वाले घड़ी के संकेत के “किनारो” पर ज्ञान पर हमला करता हैं। यह सीपीयू को काफी सरल बनाने का लाभ हैं, प्रत्येक एक डिजाइन के नजरिए से और एक घटक-गणना के नजरिए से। हालाँकि, इसमे यह कमी भी हैं कि पूरे CPU को अपने सबसे धीमे भागो पर प्रतीक्षा करनी चाहिए, हालाँकि इसके कुछ भाग बहुत तेज़ होते है। इस सीमा को काफी हद तक सीपीयू समांतरता को तेज करने की कई रणनीतियो द्वारा मुआवजा दिया गया है (नीचे देखे)।
हालाँकि, अकेले वास्तु सुधार विश्वव्यापी सिंक्रोनस सीपीयू की संपूर्ण कमियो को दूर नही करते है। उदाहरण के लिए, एक घड़ी का चिन्ह किसी अन्य विद्युत संकेत की देरी का विषय है। अधिक से अधिक जटिल सीपीयू मे उच्च क्लॉक चार्ज पूरे यूनिट मे क्लॉक साइन इन सेक्शन (सिंक्रनाइज़) को बनाए रखना कठिन बनाते है। इसने कई फैशनेबल सीपीयू को सीपीयू को खराबी के लिए ट्रिगर करने के लिए पर्याप्त रूप से एक संकेत मे देरी से बचने के लिए कई समान घड़ी संकेतको की आपूर्ति की आवश्यकता होती हैं। एक अन्य मुख्य कठिनाई, जैसे-जैसे घड़ी के शुल्क मे नाटकीय रूप से सुधार होता हैं, सीपीयू द्वारा नष्ट की जाने वाली गर्मी की मात्रा हैं। हमेशा बदलती घड़ी के कारण कई हिस्से संशोधित हो जाते है चाहे वे इस समय उपयोग किए जा रहे हो या नही। मूल रूप से, स्विच करने वाला एक हिस्सा स्थिर स्थिति मे एक घटक की तुलना मे अतिरिक्त शक्ति का उपयोग करता हैं। इसलिए, जैसे-जैसे घड़ी की फीस बढ़ेगी, वैसे-वैसे बिजली की खपत भी बढ़ेगी, जिससे सीपीयू को सीपीयू कूलिंग विकल्पो के प्रकार के भीतर अतिरिक्त गर्मी अपव्यय की आवश्यकता होगी।
अनावश्यक भागो के स्विचिंग से निपटने की एक तकनीक को क्लॉक गेटिंग के रूप मे जाना जाता है, जिसमे घड़ी के संकेत को अनावश्यक भागो मे बंद करना (उन्हे सफलतापूर्वक अक्षम करना) शामिल हैं। हालाँकि, इसे आमतौर पर लागू करना मुश्किल माना जाता है और इस तथ्य के कारण बहुत कम-शक्ति वाले डिज़ाइनो के बाहरी उपयोग को बार-बार नही देखा जाता हैं। एक उल्लेखनीय नवीनतम सीपीयू डिज़ाइन जो गहन घड़ी गेटिंग का उपयोग करता हैं, वह है आईबीएम पॉवरपीसी-आधारित क्सीनन जो Xbox 360 के भीतर उपयोग किया जाता है; इसका मतलब हैं, Xbox 360 की ऊर्जा आवश्यकताएं बहुत कम हो गई है.
Clockless CPUs
विश्व घड़ी संकेत के साथ कई मुद्दो को संबोधित करने की एक अन्य पद्धति घड़ी के संकेत को पूरी तरह से समाप्त करना है। दुनिया भर मे घड़ी के संकेत को खत्म करने से कुछ मायनो मे डिजाइन पाठ्यक्रम काफी जटिल हो जाता हैं, अतुल्यकालिक (या घड़ी रहित) डिजाइन संबंधित सिंक्रोनस डिजाइन की तुलना मे ऊर्जा खपत और गर्मी अपव्यय मे उल्लेखनीय लाभ उठाते है। जबकि काफी असामान्य, कुल एसिंक्रोनस सीपीयू का निर्माण बिना वर्ल्ड क्लॉक साइन का उपयोग किए किया गया हैं। इसके दो उल्लेखनीय उदाहरण है एआरएम अनुपालक AMULET और MIPS R3000 उपयुक्त MiniMIPS।
क्लॉक साइन को पूरी तरह से मिटाने के बजाय, कुछ सीपीयू डिज़ाइन मशीन के कुछ हिस्सो को एसिंक्रोनस होने मे सक्षम बनाते है, जैसे कि कुछ अंकगणितीय दक्षता अच्छे बिंदुओ को महसूस करने के लिए साइड सुपरस्केलर पाइपलाइनिंग के साथ एसिंक्रोनस एएलयू का उपयोग करना। हालांकि यह पूरी तरह से स्पष्ट नही है कि पूरी तरह से एसिंक्रोनस डिज़ाइन अपने सिंक्रोनस समकक्षो की तुलना मे तुलनीय या उच्च डिग्री पर कर सकते है या नही, यह स्पष्ट है कि वे कम जटिल गणित कार्यो मे कम से कम उत्कृष्ट प्रदर्शन करते है। यह, उनकी शानदार ऊर्जा खपत और गर्मी अपव्यय गुणो के साथ मिश्रित, उन्हे एम्बेडेड कंप्यूटरो के लिए बहुत उपयुक्त बनाता हैं
Voltage regulator module
कई आधुनिक सीपीयू मे एक डाई-एकीकृत ऊर्जा प्रबंधन मॉड्यूल होता हैं जो सीपीयू सर्किटरी को ऑन-डिमांड वोल्टेज प्रदान करता हैं जो इसे दक्षता और ऊर्जा खपत के बीच स्थिरता बनाए रखने की अनुमति देता हैं।
Integer vary
प्रत्येक सीपीयू एक विशेष तरीके से संख्यात्मक मूल्यो का प्रतिनिधित्व करता हैं। उदाहरण के लिए, कुछ प्रारंभिक डिजिटल कंप्यूटर सिस्टम परिचित दशमलव (आधार 10) अंक प्रणाली मान के रूप मे संख्याओ का प्रतिनिधित्व करते है, और अन्य ने टर्नरी (आधार तीन) के बराबर अतिरिक्त असामान्य अभ्यावेदन को नियोजित किया हैं। लगभग सभी फैशनेबल सीपीयू बाइनरी प्रकार मे संख्याओ को दर्शाते है, प्रत्येक अंक को “उच्च” या “निम्न” वोल्टेज के बराबर कुछ दो-मूल्यवान शारीरिक राशि द्वारा दर्शाया जाता हैं
संख्यात्मक चित्रण से संबंधित पूर्णाक संख्याओ का पैमाना और सटीकता है {कि एक} सीपीयू संकेत कर सकता हैं। एक बाइनरी सीपीयू के मामले मे, जिसे बिट्स की विविधता (एक बाइनरी एन्कोडेड पूर्णांक के महत्वपूर्ण अंक) द्वारा मापा जाता हैं, जिसे सीपीयू एक ही ऑपरेशन मे कर सकता है, जिसे आमतौर पर शब्द आकार, बिट चौड़ाई, ज्ञान पथ के रूप मे जाना जाता है। चौड़ाई, पूर्णाक परिशुद्धता, या पूर्णाक आयाम। एक सीपीयू का पूर्णाक आयाम पूर्णाक मानो की भिन्नता को निर्धारित करता है जिस पर वह सीधे कार्य कर सकता हैं। उदाहरण के लिए, एक 8-बिट सीपीयू आठ बिट्स द्वारा दर्शाए गए पूर्णांको मे सीधे हेरफेर कर सकता है, जिसमे 256 (28) असतत पूर्णाक मानो का प्रसार होता है।
पूर्णाक भिन्नता का प्रभाव उन स्मृति क्षेत्रो की विविधता पर भी पड़ सकता हैं जिन्हे सीपीयू सीधे संभाल सकता हैं (एक हैंडल एक विशेष स्मृति स्थान का प्रतिनिधित्व करने वाला एक पूर्णाक है)। उदाहरण के लिए, यदि एक बाइनरी सीपीयू 32 बिट्स का उपयोग करता हैं, तो यह 232 मेमोरी क्षेत्रो को सीधे हैंडल कर सकता हैं। इस सीमा को दरकिनार करने के लिए और विभिन्न विभिन्न कारणो के लिए, कुछ सीपीयू तंत्र (बैंक स्विचिंग के अनुरूप) का उपयोग करते है जो आगे की यादो को संबोधित करने मे सक्षम बनाता हैं।
बड़े शब्द आकार वाले सीपीयू को अतिरिक्त सर्किटरी की आवश्यकता होती हैं और परिणामस्वरूप वे शारीरिक रूप से बड़े होते है, अधिक खर्च करते है और अधिक ऊर्जा खाते है (और इस वजह से अतिरिक्त गर्मी उत्पन्न करते है)। नतीजतन, छोटे 4- या 8-बिट माइक्रोकंट्रोलर आमतौर पर आधुनिक कार्यो में उपयोग किए जाते है, भले ही बहुत बड़े वाक्यांश आकार वाले सीपीयू (16, 32, 64, यहां तक कि 128-बिट के समान) पाए जा सकते हैं।
जब अधिक दक्षता की आवश्यकता होती हैं, फिर भी, बड़े वाक्यांश आयाम (बड़े ज्ञान रेंज और हैंडल क्षेत्र) के फायदे नुकसान से अधिक हो सकते है। एक सीपीयू में पीछे के आयाम और मूल्य को मापने के लिए वाक्यांश आयाम से छोटे ज्ञान पथ हो सकते है । उदाहरण के लिए, भले ही आईबीएम सिस्टम/360 निर्देश सेट 32-बिट निर्देश सेट था, सिस्टम/360 मॉडल 30 और मॉडल 40 मे अंकगणितीय तार्किक इकाई के भीतर 8-बिट ज्ञान पथ थे,
इसलिए {कि एक} 32-बिट जोड़े ऑपरेंड के प्रत्येक 8 बिट्स के लिए 4 चक्रो की आवश्यकता होती है, और इस बात की परवाह किए बिना कि मोटोरोला 68000 श्रृंखला निर्देश सेट 32-बिट निर्देश सेट था, मोटोरोला 68000 और मोटोरोला 68010 में अंकगणितीय तार्किक इकाई के भीतर 16-बिट ज्ञान पथ थे, इसलिए {कि a} 32-बिट ऐड के लिए दो चक्रों की आवश्यकता होती हैं।
प्रत्येक कमी और बेहतर बिट लंबाई द्वारा प्रदान किए गए कुछ लाभो को प्राप्त करने के लिए, कई निर्देश सेटो मे पूर्णाक और फ़्लोटिंग-पॉइंट ज्ञान के लिए पूरी तरह से अलग-अलग बिट चौड़ाई होती हैं, जिससे सीपीयू को उस निर्देश को लागू करने की अनुमति मिलती हैं जो गैजेट के विभिन्न हिस्सो के लिए पूरी तरह से अलग बिट चौड़ाई होती हैं। . उदाहरण के लिए, आईबीएम सिस्टम/360 इंस्ट्रक्शन सेट मुख्य रूप से 32 बिट का था, हालांकि उच्च सटीकता की सुविधा के लिए 64-बिट फ्लोटिंग पॉइंट वैल्यू का समर्थन करता था और फ्लोटिंग लेवल नंबरों मे भिन्नता थी।
सिस्टम/360 मॉडल 65 मे दशमलव और फिक्स्ड-पॉइंट बाइनरी अंकगणित के लिए 8-बिट योजक और फ्लोटिंग-पॉइंट अंकगणित के लिए 60-बिट योजक था। कई बाद के सीपीयू डिजाइन संबंधित संयुक्त बिट चौड़ाई का उपयोग करते है, खासकर जब प्रोसेसर को सामान्य प्रयोजन के उपयोग के लिए माना जाता हैं, जहां पूर्णाक और फ्लोटिंग स्तर की कार्यक्षमता की एक सस्ती स्थिरता की आवश्यकता होती हैं।
Parallelism
पिछले भाग मे आपूर्ति किए गए सीपीयू के आवश्यक संचालन का विवरण केवल उस प्रकार का वर्णन करता हैं जो एक सीपीयू ले सकता हैं। इस प्रकार का सीपीयू, जिसे अक्सर सबस्केलर के रूप मे जाना जाता हैं, एक समय मे सूचना के एक या दो आइटम पर एक निर्देश को संचालित और निष्पादित करता हैं, जो प्रति घड़ी चक्र (आईपीसी <1) के एक निर्देश से कम हैं।
ऑफ़र का यह कोर्स सबस्केलर सीपीयू मे एक अंतर्निहित अक्षमता को जन्म देता हैं। चूंकि एक समय मे केवल एक निर्देश निष्पादित किया जाता हैं, इसलिए आपका पूरा सीपीयू अगले निर्देश को जारी रखने से पहले उस निर्देश को समाप्त करने के लिए तत्पर होना चाहिए। एक परिणाम के रूप मे, सबस्केलर सीपीयू उन दिशाओ पर “लटका हुआ” हो जाएगा जो निष्पादन को समाप्त करने के लिए कई घड़ी चक्र लेते है। यहां तक कि एक दूसरी निष्पादन इकाई (नीचे देखे) को भी शामिल करने से दक्षता मे बहुत वृद्धि नहीं होती हैं; अपेक्षाकृत एक मार्ग से लटका दिया जा रहा हैं, अब दो रास्ते लटकाए गए है और अप्रयुक्त ट्रांजिस्टर की विविधता बढ़ गई हैं। यह डिज़ाइन, जिससे CPU की निष्पादन संपत्ति एक समय मे केवल एक निर्देश पर कार्य कर सकती हैं, संभवतः केवल स्केलर दक्षता (एक निर्देश प्रति घड़ी चक्र, IPC = 1) प्राप्त कर सकती हैं. हालांकि, दक्षता लगभग हर समय उप-वर्ग हैं (प्रति घड़ी चक्र में एक निर्देश से कम, आईपीसी <1)।
स्केलर और उच्च दक्षता का एहसास करने के प्रयासो के परिणामस्वरूप बहुत सी डिज़ाइन पद्धतिया है जो सीपीयू को बहुत कम रैखिक और समानांतर मे अतिरिक्त व्यवहार करने के लिए ट्रिगर करती है। सीपीयू मे समानता का जिक्र करते समय, इन डिज़ाइन रणनीतियो को वर्गीकृत करने के लिए आमतौर पर दो वाक्यांशों का उपयोग किया जाता है.
- निर्देश-स्तरीय समानता (ILP), जो उस गति का विस्तार करना चाहता हैं जिस पर CPU के अंदर दिशाओ को निष्पादित किया जाता हैं (अर्थात, ऑन-डाई निष्पादन संपत्तियो का उपयोग करके विस्तार करने के लिए);
- कार्य-स्तरीय समानांतरवाद (टीएलपी), जो विभिन्न प्रकार के थ्रेड्स या प्रक्रियाओ को विस्तारित करने के लिए कार्य करता हैं सीपीयू समवर्ती रूप से निष्पादित कर सकता हैं।
- प्रत्येक कार्यप्रणाली उन तरीको में भिन्न होती हैं जिनके द्वारा उन्हे लागू किया जाता हैं, एक उपयोगिता के लिए सीपीयू की दक्षता बढ़ाने मे वे सापेक्ष प्रभावशीलता के अलावा।
उन्नत समानांतरवाद के लिए सबसे अच्छी रणनीतियो मे से एक हैं , पूर्व निर्देश के निष्पादन के पूरा होने से पहले निर्देश लाने और डिकोडिंग के प्राथमिक चरण शुरू करना। यह एक तरीका हैं जिसे अक्सर निर्देश पाइपलाइनिग के रूप मे जाना जाता हैं , और लगभग सभी आधुनिक सामान्य प्रयोजन सीपीयू मे उपयोग किया जाता हैं । पाइपलाइनिंग निष्पादन पथ को असतत चरणो मे तोड़कर एक समय मे कई निर्देशो को निष्पादित करने की अनुमति देता हैं। यह पृथक्करण एक मीटिंग लाइन की तुलना मे होगा, जिसके द्वारा एक निर्देश को निष्पादन पाइपलाइन से बाहर निकलने और सेवानिवृत्त होने तक प्रत्येक चरण मे अतिरिक्त पूर्ण किया जाता हैं।
पाइपलाइनिंग, फिर भी, एक परिदृश्य के लिए अवसर प्रदान करता हैं जहां बाद के ऑपरेशन को पूरा करने के लिए पहले के ऑपरेशन के परिणामो की आवश्यकता होती हैं; एक स्थिति जिसे आमतौर पर ज्ञान निर्भरता लड़ाई कहा जाता हैं। इसलिए पाइपलाइन किए गए प्रोसेसर को इस प्रकार की परिस्थितियो के लिए परीक्षण करना चाहिए और यदि आवश्यक हो तो पाइपलाइन के एक हिस्से मे देरी करनी चाहिए। एक पाइपलाइन वाला प्रोसेसर बहुत व्यावहारिक रूप से स्केलर हो सकता हैं, जो केवल पाइपलाइन स्टालो (एक चरण मे दो घड़ी चक्र खर्च करने वाला निर्देश) द्वारा बाधित होता हैं।
निर्देश पाइपलाइनिंग मे सुधार के कारण CPU भागो के निष्क्रिय समय के भीतर अतिरिक्त कमी आई हैं । डिज़ाइन जिन्हे सुपरस्केलर कहा जा सकता हैं उनमे एक लंबी निर्देश पाइपलाइन और कई समान निष्पादन इकाइया शामिल हैं, जैसे लोड-स्टोर इकाइयां, अंकगणित-तर्क इकाइयां, फ़्लोटिंग-पॉइंट इकाइयां और पता पीढ़ी इकाइयां। एक सुपरस्केलर पाइपलाइन मे, दिशाओ को सीखा जाता हैं और एक डिस्पैचर को सौप दिया जाता हैं, जो यह तय करता हैं कि दिशाओ को समानांतर (समवर्ती) मे निष्पादित किया जाएगा या नही। यदि ऐसा हैं, तो उन्हे निष्पादन मॉडल में भेज दिया जाता हैं, जिसके परिणामस्वरूप उनका एक साथ निष्पादन होता हैं। मूल रूप से, दिशाओ की विविधता {कि एक} सुपरस्केलर सीपीयू एक चक्र मे भर जाएगा, यह उन दिशाओ की विविधता पर निर्भर करता हैं जो एक साथ निष्पादन मॉडल को भेजने के लिए तैयार है।
सुपरस्केलर सीपीयू संरचना के डिजाइन के भीतर अधिकांश समस्या
एक कुशल डिस्पैचर बनाने मे निहित हैं। डिस्पैचर तेजी से यह तय करने की क्षमता चाहता हैं कि निर्देशो को समानांतर मे निष्पादित किया जा सकता है या नही, साथ ही उन्हे इस तरह से प्रेषित करने के लिए कि कई निष्पादन आइटम संभावित रूप से व्यस्त रखने के लिए। इसके लिए आवश्यक हैं कि निर्देश पाइपलाइन को आम तौर पर संभावित रूप से भरा जाए और इसके लिए महत्वपूर्ण मात्रा मे CPU कैश की आवश्यकता हो। यह अतिरिक्त रूप से जोखिम से बचने की रणनीतिया बनाता है जैसे शाखा भविष्यवाणी, सट्टा निष्पादन, रजिस्टर का नाम बदलना, आउट-ऑफ-ऑर्डर निष्पादन और दक्षता की उच्च श्रेणी को बनाए रखने के लिए आवश्यक लेनदेन संबंधी स्मृति। एक सशर्त निर्देश कौन सा विभाग (या पथ) लेगा, यह भविष्यवाणी करने का प्रयास करके, सीपीयू उन उदाहरणो की संख्या को कम कर सकता हैं जो आपकी पूरी पाइपलाइन को सशर्त निर्देश पूरा होने तक प्रतीक्षा करनी चाहिए। सट्टा निष्पादन आम तौर पर कोड के कुछ हिस्सो को निष्पादित करके मामूली दक्षता प्रदान करता है जो सशर्त ऑपरेशन पूर्ण होने के बाद नही चाहिए। आउट-ऑफ-ऑर्डर निष्पादन उस क्रम को काफी हद तक पुनर्व्यवस्थित करता हैं जिसके दौरान सूचना निर्भरता के कारण देरी को कम करने के लिए निर्देशो को निष्पादित किया जाता हैं। सिंगल इंस्ट्रक्शन स्ट्रीम, मल्टीपल डेटा स्ट्रीम के मामले मे – एक ऐसा मामला जब एक ही तरह की बहुत सारी जानकारी को प्रोसेस किया जाना चाहिए – ट्रेडी प्रोसेसर पाइपलाइन के तत्वो को निष्क्रिय कर सकते है ताकि जब एक ही निर्देश कई बार निष्पादित हो, तो सीपीयू फ़ेच और डीकोड चरणो को छोड़ देता हैं और इस प्रकार कुछ निश्चित घटनाओ पर दक्षता मे वृद्धि करेगा, विशेष रूप से अत्यंत नीरस प्रोग्राम इंजनो में वीडियो निर्माण सॉफ्टवेयर प्रोग्राम और पिक्चर प्रोसेसिंग की याद दिलाता हैं।
उस स्थिति मे जहा सीपीयू का केवल एक हिस्सा सुपरस्केलर होता है, आधा जो शेड्यूलिंग स्टालो के परिणामस्वरूप दक्षता दंड का सामना नही करता हैं। इंटेल पी5 पेंटियम मे दो सुपरस्केलर एएलयू थे जो प्रत्येक घड़ी चक्र मे एक निर्देश के लिए व्यवस्थित हो सकते है, हालांकि इसका एफपीयू नही कर सका। इस प्रकार P5 पूर्णाक सुपरस्केलर था लेकिन फ्लोटिंग लेवल सुपरस्केलर नही। P5 संरचना के लिए Intel के उत्तराधिकारी, P6 ने अपने फ्लोटिंग स्तर विकल्पो मे सुपरस्केलर प्रतिभाओ को जोड़ा।
सरल पाइपलाइनिंग और सुपरस्केलर डिज़ाइन एक सीपीयू के आईएलपी को प्रति घड़ी चक्र मे एक निर्देश से अधिक शुल्क पर निर्देशो को निष्पादित करने की अनुमति देकर बढ़ाते है। अधिकांश आधुनिक CPU डिज़ाइन कम से कम काफी सुपरस्केलर होते है, और व्यावहारिक रूप से अंतिम दशक के भीतर डिज़ाइन किए गए सभी सामान्य लक्ष्य CPU सुपरस्केलर होते है। बाद के वर्षो मे उच्च-आईएलपी कंप्यूटर सिस्टम को डिजाइन करने पर कुछ जोर सीपीयू के {हार्डवेयर} और इसके सॉफ्टवेयर प्रोग्राम इंटरफेस, या इंस्ट्रक्शन सेट आर्किटेक्चर (आईएसए) मे स्थानांतरित कर दिया गया है। बहुत लंबे निर्देश शब्द (वीएलआईडब्ल्यू) की तकनीक कुछ आईएलपी को सॉफ्टवेयर प्रोग्राम द्वारा सीधे निहित मे बदलने का कारण बनती हैं, आईएलपी को बढ़ावा देने मे सीपीयू के काम को कम करती हैं और इस तरह डिजाइन जटिलता को कम करती हैं।
कार्य-स्तर समानता
दक्षता प्राप्त करने की एक अन्य तकनीक समानांतर मे कई थ्रेड्स या प्रक्रियाओं को निष्पादित करना हैं। विश्लेषण के इस स्थान को समानांतर कंप्यूटिंग कहा जाता हैं। फ्लिन की टैक्सोनॉमी मे, इस तकनीक को मल्टीपल इंस्ट्रक्शन स्ट्रीम, मल्टीपल डेटा स्ट्रीम (MIMD) कहा जाता हैं।
इस लक्ष्य के लिए इस्तेमाल की जाने वाली एक तकनीक मल्टीप्रोसेसिंग (एमपी) थी। इस तकनीक के प्रारंभिक स्वाद को सिमेट्रिक मल्टीप्रोसेसिंग (एसएमपी) नाम दिया गया हैं, जहा सीपीयू की एक छोटी संख्या उनके स्मृति प्रणाली के एक सुसंगत दृश्य को साझा करती हैं। इस योजना मे, स्मृति के लगातार अप-टू-डेट दृश्य को बनाए रखने के लिए प्रत्येक सीपीयू के पास अतिरिक्त हार्डवेयर होता हैं। स्मृति के पुराने विचारो से बचकर, CPU एक ही प्रोग्राम मे सहयोग कर सकते है और पैकेज एक CPU से दूसरे CPU मे माइग्रेट कर सकते है। सहयोग करने वाले CPU की संख्या को कुछ हद तक बढ़ाने के लिए, उन्नीस नब्बे के दशक मे गैर-यूनिफ़ॉर्म मेमोरी एक्सेस (NUMA) और निर्देशिका-आधारित सुसंगतता प्रोटोकॉल जैसी योजनाओ को लॉन्च किया गया हैं। SMP प्रोग्राम सीपीयू की एक छोटी संख्या तक सीमित है जबकि NUMA प्रोग्राम 1000 प्रोसेसर के साथ बनाए गए है। प्रारंभ में, प्रोसेसर के बीच इंटरकनेक्ट को लागू करने के लिए कई असतत सीपीयू और बोर्डो का उपयोग करके मल्टीप्रोसेसिंग का निर्माण किया गया था। जब प्रोसेसर और उनके इंटरकनेक्ट सभी एक ही चिप पर किए जाते है, तो इस तकनीक को चिप-लेवल मल्टीप्रोसेसिंग (सीएमपी) और एक चिप को मल्टी-कोर प्रोसेसर कहा जाता हैं।
बाद मे यह स्वीकार किया गया कि एक ही कार्यक्रम के साथ बारीक अनाज समानता मौजूद थी। एक एकल प्रोग्राम को कई थ्रेड्स (या सुविधाओं) की आवश्यकता हो सकती हैं जिन्हे व्यक्तिगत रूप से या समानांतर मे निष्पादित किया जा सकता हैं। इस विशेषज्ञता के कुछ शुरुआती उदाहरणो मे इनपुट/आउटपुट प्रोसेसिंग की गई हैं, जो सीधे मेमोरी एक्सेस की याद दिलाता हैं, जो गणना थ्रेड से अलग थ्रेड के रूप मे होता हैं। इस विशेषज्ञता के लिए एक अतिरिक्त सामान्य रणनीति सत्तर के दशक मे शुरू की गई थी जब तकनीको को समानांतर मे कई गणना धागे चलाने के लिए डिज़ाइन किया गया था। इस विशेषज्ञता को मल्टी-थ्रेडिंग (एमटी) नाम दिया गया हैं। इस रणनीति को मल्टीप्रोसेसिंग की तुलना मे अधिक लागत प्रभावी माना जाता हैं, क्योकि एमपी के मामले मे एमटी बनाम आपके पूरे सीपीयू की सहायता के लिए सीपीयू के अंदर केवल कुछ तत्वो को दोहराया जाता है। एमटी मे, कैश के साथ निष्पादन आइटम और स्मरण प्रणाली कई थ्रेड्स के बीच साझा की जाती है। एमटी का दोष यह हैं कि मल्टीथ्रेडिंग के लिए हार्डवेयर सपोर्ट एमपी की तुलना मे सॉफ्टवेयर प्रोग्राम मे अधिक देखा जाता हैं और इस प्रकार एमटी की सहायता के लिए सुपरवाइजर सॉफ्टवेयर प्रोग्राम जैसे कार्य तकनीको को बड़े संशोधनो का सामना करना पड़ता हैं। एक प्रकार का एमटी जो किया गया था उसे टेम्पोरल मल्टीथ्रेडिंग नाम दिया गया हैं, जहा एक थ्रेड को तब तक क्रियान्वित किया जाता हैं जब तक कि यह ठप नही हो जाता हैं, बाहरी स्मृति से वापस आने के लिए जानकारी के लिए तैयार हैं। इस योजना मे, सीपीयू तब तेजी से एक अलग थ्रेड मे बदल जाएगा जो चलाने मे सक्षम है, परिवर्तन आमतौर पर एक सीपीयू घड़ी चक्र मे समाप्त होता है, जैसे कि अल्ट्रास्पार्क टी 1। एक अन्य प्रकार का एमटी एक साथ मल्टीथ्रेडिंग है, कई थ्रेड्स से जगह की दिशा एक सीपीयू घड़ी चक्र के अंदर समानांतर मे निष्पादित की जाती है।
उन्नीस सत्तर के दशक से 2000 के दशक की शुरुआत तक, अत्यधिक दक्षता वाले सामान्य लक्ष्य सीपीयू को डिजाइन करने मे मुख्य लक्ष्य काफी हद तक पाइपलाइनिंग, कैश, सुपरस्केलर निष्पादन, आउट-ऑफ-ऑर्डर निष्पादन जैसे अनुप्रयुक्त विज्ञान के माध्यम से अत्यधिक आईएलपी प्राप्त करना था। , और इसी तरह। इस पैटर्न की परिणति विशाल, शक्ति-भूखे सीपीयू जैसे इंटेल पेंटियम 4 मे हुई। 2000 के दशक की शुरुआत तक, सीपीयू डिजाइनरो को आईएलपी रणनीतियो से अधिक दक्षता प्राप्त करने से रोक दिया गया था, क्योकि सीपीयू काम करने की आवृत्तियो और आवश्यक स्मृति कार्य आवृत्तियो के बीच बढ़ती असमानता के कारण अतिरिक्त गूढ़ ILP रणनीतियो के कारण CPU ऊर्जा अपव्यय को बढ़ाना।
सीपीयू डिजाइनरो ने तब लेन-देन प्रसंस्करण जैसी व्यावसायिक कंप्यूटिंग बाजारो से अवधारणाओ को उधार लिया था, जहां कई पैकेजो की संयोजन दक्षता, जिसे अक्सर थ्रूपुट कंप्यूटिंग के रूप मे जाना जाता हैं, एकल थ्रेड या पाठ्यक्रम की दक्षता से अधिक महत्वपूर्ण थी।
जोर के इस उलटफेर का सबूत जुड़वा और अतिरिक्त कोर प्रोसेसर डिजाइनो के प्रसार से हैं और विशेष रूप से, इंटेल के नए डिजाइन इसकी बहुत कम सुपरस्केलर पी 6 संरचना से मिलते जुलते है। एक्सबॉक्स 360 के ट्रिपल की तरह ही कई वीडियो गेम कंसोल सीपीयू के अलावा, कई प्रोसेसर घरो मे देर से डिजाइन सीएमपी प्रदर्शित करते है, साथ मे x86-64 ओपर्टन और एथलॉन 64 एक्स 2, स्पार्क अल्ट्रास्पार्क टी 1, आईबीएम पावर 4 और पावर 5। कोर पावरपीसी डिज़ाइन, और प्लेस्टेशन 3 का 7-कोर सेल माइक्रोप्रोसेसर
डेटा समानता
बहुत कम बार-बार लेकिन प्रोसेसर के अधिक से अधिक आवश्यक प्रतिमान (और निश्चित रूप से, सामान्य रूप से कंप्यूटिंग) ज्ञान समानता के साथ प्रदान करता है। पहले बताए गए सभी प्रोसेसर किसी न किसी प्रकार की स्केलर मशीन के रूप मे जाने जाते है। जैसा कि शीर्षक से पता चलता हैं, वेक्टर प्रोसेसर 1 निर्देश के संदर्भ मे सूचना की कई वस्तुओ का ध्यान रखते है। यह स्केलर प्रोसेसर के विपरीत हैं, जो प्रत्येक निर्देश के लिए जानकारी के एक टुकड़े का ध्यान रखता हैं। फ्लिन की टैक्सोनॉमी का उपयोग करते हुए, ज्ञान से मुकाबला करने की इन दो योजनाओ को आमतौर पर सिंगल इंस्ट्रक्शन स्ट्रीम, कई नॉलेज स्ट्रीम (SIMD) और सिंगल इंस्ट्रक्शन स्ट्रीम, सिंगल नॉलेज स्ट्रीम (SISD) के रूप मे जाना जाता हैं। सूचना के वैक्टर का ख्याल रखने वाले प्रोसेसर बनाने मे अच्छी उपयोगिता उन कर्तव्यो को अनुकूलित करने मे निहित हैं जो समान संचालन (उदाहरण के लिए, एक योग या एक डॉट उत्पाद) की आवश्यकता होती हैं जो सूचना के बड़े सेट पर किए जाते है। इनमे से कुछ कर्तव्यो के कुछ पारंपरिक उदाहरणो मे वैज्ञानिक और इंजीनियरिंग कर्तव्यो की कई किस्मो के अलावा मल्टीमीडिया उद्देश्य (फोटो, वीडियो और ध्वनि) शामिल है। जबकि एक स्केलर प्रोसेसर को जानकारी के एक सेट मे हर निर्देश और मूल्य को लाने, डिकोड करने और निष्पादित करने की आपकी पूरी तकनीक को पूरा करना चाहिए, एक वेक्टर प्रोसेसर एक निर्देश के साथ अपेक्षाकृत बड़े पैमाने पर जानकारी के सेट पर एक ही ऑपरेशन कर सकता हैं। यह मुश्किल से संभव है जब आवेदन करने के लिए कई चरणो की आवश्यकता होती है जो एक ऑपरेशन को सूचना के एक बड़े सेट पर लागू करते है।
अधिकांश प्रारंभिक वेक्टर प्रोसेसर, जैसे कि क्रे-1, वस्तुतः पूरी तरह से वैज्ञानिक विश्लेषण और क्रिप्टोग्राफी कार्यो से संबंधित थे। हालाँकि, जैसे-जैसे मल्टीमीडिया बड़े पैमाने पर डिजिटल मीडिया मे स्थानांतरित हो गया हैं, सामान्य प्रयोजन के प्रोसेसर मे कुछ प्रकार के SIMD की आवश्यकता महत्वपूर्ण हो गई हैं। फ्लोटिंग-पॉइंट इकाइयो को शामिल करने के कुछ ही समय बाद सामान्य-प्रयोजन प्रोसेसर मे सामान्य होने लगे, SIMD निष्पादन मॉडल के लिए विनिर्देश और कार्यान्वयन अतिरिक्त रूप से सामान्य-उद्देश्य वाले प्रोसेसर के लिए दिखाई देने लगे। [कब?] उन शुरुआती SIMD स्पेक्स मे से कुछ – जैसे HP’s मल्टीमीडिया एक्सेलेरेशन एक्स्टेंशन्स (MAX) और इंटेल का MMX – केवल पूर्णाक था। यह कुछ सॉफ्टवेयर प्रोग्राम बिल्डरो के लिए एक बड़ी बाधा साबित हुई, क्योकि सिम से लाभ प्राप्त करने वाले अधिकांश फ़ंक्शन मुख्य रूप से फ्लोटिंग-पॉइंट नंबरो का ख्याल रखते है। प्रगतिशील रूप से, बिल्डरो ने इन शुरुआती डिज़ाइनो को परिष्कृत और कई बार फैशनेबल SIMD स्पेक्स मे बनाया, जो अक्सर एक निर्देश सेट आर्किटेक्चर (ISA) से संबंधित होते है। कुछ उल्लेखनीय फैशनेबल उदाहरणो मे Intel का स्ट्रीमिंग SIMD एक्सटेंशन (SSE) और PowerPC से संबंधित AltiVec (अक्सर VMX के रूप मे जाना जाता है) शामिल हैं।
हार्डवेयर प्रदर्शन काउंटर
कई फैशनेबल आर्किटेक्चर (एम्बेडेड के साथ) आमतौर पर हार्डवेयर प्रदर्शन काउंटर (एचपीसी) को शामिल करते है, जो निम्न-स्तरीय (निर्देश-स्तर) वर्गीकरण, बेंचमार्किग, डिबगिंग या ऑपरेटिंग सॉफ्टवेयर प्रोग्राम मेट्रिक्स के मूल्यांकन की अनुमति देता है। एचपीसी का उपयोग सॉफ्टवेयर प्रोग्राम के असामान्य या संदिग्ध अभ्यास को खोजने और विश्लेषण करने के लिए भी किया जा सकता हैं, जो रिटर्न-ओरिएंटेड प्रोग्रामिंग (आरओपी) या सिग्रेटर्न-ओरिएंटेड प्रोग्रामिंग (एसआरओपी) के कारनामो आदि के अनुरूप है। यह आमतौर पर सॉफ़्टवेयर-सुरक्षा समूहो द्वारा दुर्भावनापूर्ण बाइनरी अनुप्रयोगो के मूल्यांकन और खोज के लिए समाप्त किया जाता है।
कई मुख्य वितरक (आईबीएम, इंटेल, एएमडी, और एआरएम आदि के अनुरूप।) सॉफ्टवेयर प्रोग्राम इंटरफेस पेश करते है (आमतौर पर सी/सी ++ में लिखा जाता हैं) जिनका उपयोग मेट्रिक्स प्राप्त करने के इरादे से सीपीयू रजिस्टरो से एकत्रित जानकारी के लिए किया जा सकता हैं। ] ऑपरेटिंग सिस्टम डिस्ट्रीब्यूटर्स अतिरिक्त रूप से सॉफ्टवेयर प्रोग्राम जैसे perf (लिनक्स) को दस्तावेज़, बेंचमार्क, या सीपीयू अवसरो के संचालन कर्नेल और कार्यो का पता लगाने के लिए पेश करते है।
Virtual CPUs
क्लाउड कंप्यूटिंग मे उप-विभाजित CPU संचालन को डिजिटल सेंट्रल प्रोसेसिंग मॉडल (vCPUs) मे शामिल किया जा सकता हैं।
बंच एक शारीरिक मशीन के बराबर डिजिटल हैं, जिस पर एक डिजिटल सिस्टम काम कर रहा है। जब कई शारीरिक मशीने एक साथ काम कर रही होती है और समग्र रूप से प्रबंधित होती है, तो समूहीकृत कंप्यूटिंग और स्मृति संपत्ति एक क्लस्टर की तरह होती हैं। कुछ कार्यक्रमो मे, क्लस्टर से गतिशील रूप से जोड़ना और निकालना संभव हैं। एक संख्या और क्लस्टर स्तर पर प्राप्य संसाधनो को अद्भुत ग्रैन्युलैरिटी के साथ संसाधन पूल मे विभाजित किया जा सकता है।
Performance
एक प्रोसेसर की दक्षता या गति कई अलग-अलग घटको के बीच, क्लॉक चार्ज (आमतौर पर हर्ट्ज के गुणको मे दी गई) और प्रति घड़ी दिशाओ (आईपीसी) पर निर्भर करती हैं, जो सामूहिक रूप से निर्देश प्रति सेकंड (आईपीएस) के घटक है। सीपीयू बाहर ले जा सकता हैं। कई रिपोर्ट किए गए IPS मूल्यो ने कुछ शाखाओ के साथ सिंथेटिक निर्देश अनुक्रमो पर “पीक” निष्पादन शुल्क का प्रतिनिधित्व किया हैं, जबकि आजीवन कार्यभार मे दिशाओ और कार्यो का मिश्रण शामिल हैं, जिनमे से कुछ को दूसरो की तुलना मे निष्पादित करने मे अधिक समय लगता हैं। मेमोरी पदानुक्रम की दक्षता अतिरिक्त रूप से प्रोसेसर दक्षता को प्रभावित करती हैं, एक समस्या जिसे एमआईपीएस गणनाओ मे मुश्किल से सोचा जाता हैं। उन मुद्दो के कारण, विभिन्न मानकीकृत परीक्षाएं, जिन्हे आमतौर पर इस उद्देश्य के लिए “बेंचमार्क” के रूप मे संदर्भित किया जाता हैं – विशेष रूप से उपयोग किए जाने वाले कार्यो मे वास्तविक कुशल दक्षता को मापने की कोशिश करने के लिए विकसित किए गए है।
मल्टी-कोर प्रोसेसर का उपयोग करके कंप्यूटर सिस्टम की प्रोसेसिंग दक्षता को बढ़ाया जाता हैं, जो मूल रूप से दो या अतिरिक्त विशेष व्यक्ति प्रोसेसर (इस अर्थ मे कोर के रूप मे संदर्भित) को एक अंतर्निर्मित सर्किट मे प्लग कर रहा हैं। आदर्श रूप से, एक ट्विन कोर प्रोसेसर एकल कोर प्रोसेसर की तुलना मे व्यावहारिक रूप से दोगुना प्रभावी हो सकता हैं। निरीक्षण मे, अपूर्ण सॉफ्टवेयर प्रोग्राम एल्गोरिदम और कार्यान्वयन के कारण दक्षता हासिल करना बहुत छोटा है, केवल लगभग 50%। एक प्रोसेसर (अर्थात दोहरे कोर, क्वाड-कोर, और इसी तरह) मे कोर की विविधता बढ़ाने से उस कार्यभार मे वृद्धि होगी जिससे निपटा जा सकता है। इसका तात्पर्य यह है कि प्रोसेसर अब कुछ अतुल्यकालिक अवसरो, व्यवधानो आदि को संभाल सकता हैं। जो अतिभारित होने पर सीपीयू पर भारी पड़ सकता हैं। प्रसंस्करण संयंत्र मे इन कोर को पूरी तरह से अलग फर्श माना जा सकता है, जिसमे प्रत्येक फर्श एक विशेष प्रक्रिया से निपटता हैं। कभी-कभी, ये कोर उनके साथ लगे कोर के समान कर्तव्यो से निपटेगे यदि डेटा से निपटने के लिए एक एकल कोर पर्याप्त नही हैं।
हाल के सीपीयू की विशेष क्षमताओ के कारण, एक साथ मल्टीथ्रेडिंग और अनकोर के समान, जिसमे उन्नत उपयोग, निगरानी दक्षता रेंज और {हार्डवेयर} का लक्ष्य रखते हुए सटीक सीपीयू संपत्तियो को साझा करना शामिल है, एक अतिरिक्त जटिल प्रक्रिया बन गई है। प्रतिक्रिया के रूप मे, कुछ सीपीयू अतिरिक्त {हार्डवेयर} तर्क को लागू करते है जो सीपीयू के विभिन्न तत्वो के सटीक उपयोग को प्रदर्शित करता हैं और सॉफ्टवेयर प्रोग्राम के लिए विभिन्न काउंटरो को उपलब्ध कराता हैं; एक उदाहरण हैं इंटेल का प्रदर्शन काउंटर मॉनिटर तकनीकी जानकारी।
what is processor ? पूरी जानकारी हिंदी मे
हमे उम्मीद है की आपको हमारे आज का ये article “what is processor ?“जरूर पसंद आया होगा।